
The Big 5 And Their AI Stacks Part II: Implications
Digging into what we can learn behind the AI strategies of Microsoft, Amazon, Google, Snowflake, and Databricks


In our last post, we summarized how each of the “Big 5 Cloud Providers” - Microsoft, Amazon, Google, Snowflake, and Databricks - were building out their AI stacks and strategies, specifically across the Model, Infrastructure, and Application layers. The post elicited plenty of great commentary and feedback, not least of which came from Databricks announcing their open-source LLM “DBRX” the previous day! With the rapid pace of change happening in the AI world daily, we updated our table to better reflect the latest products at each of the layers.
In this post, we’ll explore some of the key learnings and implications behind these strategic moves by the Big 5, and what it could mean for AI startups competing at these levels.

Cloud Hyperscalers Are Becoming AI Hyperscalers
In 2006, AWS launched its first major cloud product with S3 (storage), quickly followed by EC2 (compute). Two years later in 2008, both Google and Microsoft jumped into the cloud computing game, launching App Engine and Windows Azure respectively. Fast forward to today, and each of these major hyperscalers offer hundreds of products covering virtually every aspect of cloud computing, from databases to containers to networking and security. Collectively, AWS + GCP + Azure generate nearly ~$200M run-rate revenue.
Just as the hyperscalers built out products at every layer of the cloud computing stack (IaaS; PaaS; and SaaS), so are they doing the same at every layer of the AI stack (Model; Infrastructure; and Application). In other words, they are following a similar pattern of product suite build-out that spurred their massive growth over the past ~20 years. They will offer a “one-stop shop” for customers to fulfill all of their cloud and AI needs in a single place, if they prefer.
Of course, just as the growth of the hyperscalers’ product suite didn’t necessitate the death of individual startups as many predicted (see: Snowflake vs. Redshift; MongoDB vs. DynamoDB; DataDog vs. Cloudwatch; etc.), so do we fully believe that there will be plenty of room for AI startups to compete at virtually every layer of the stack. What’s fascinating in this era is startups of the former era (like Databricks) are now established giants that are aggressively competing to build proprietary models and infrastructure.

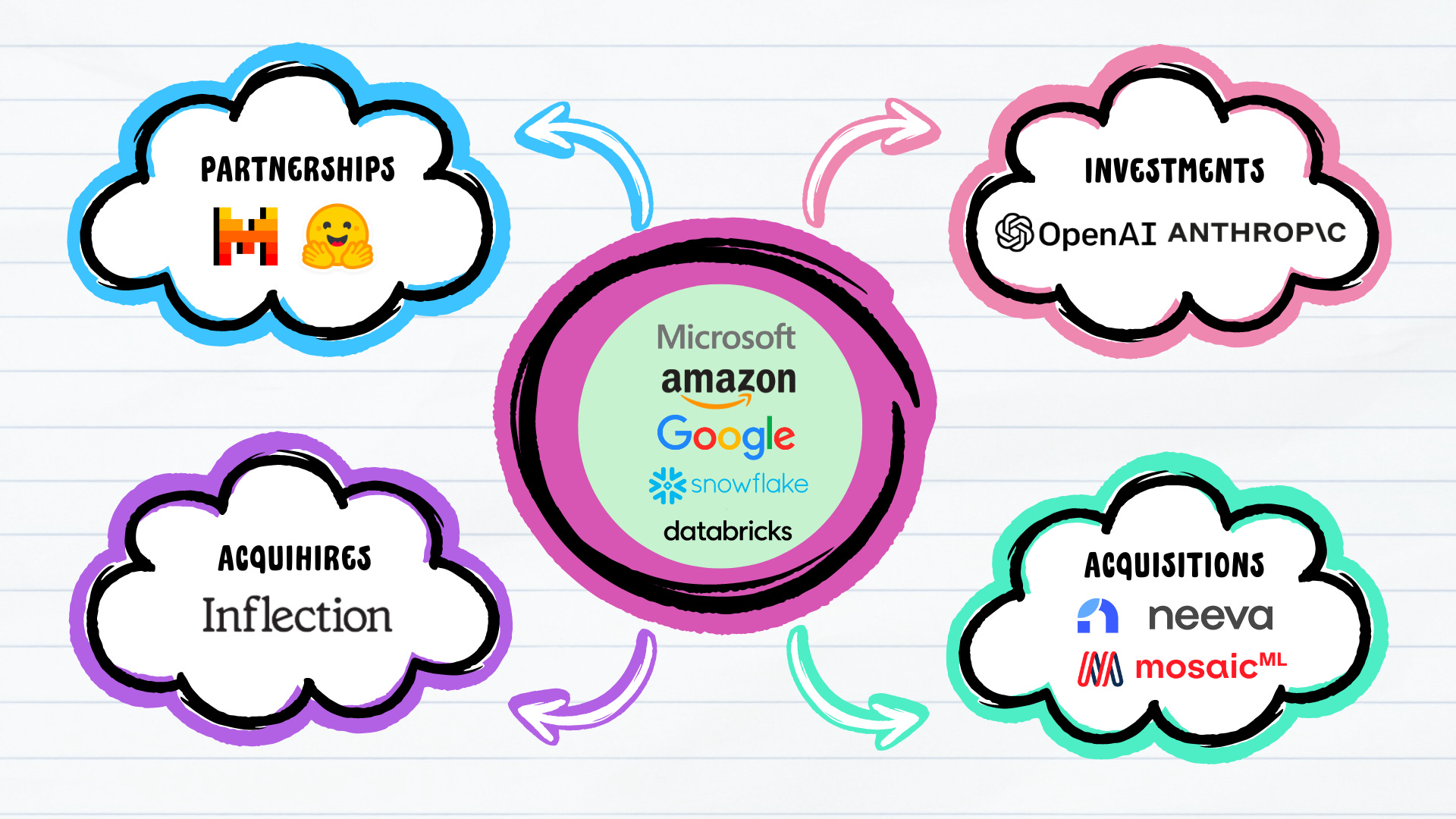
Partnerships & Acquisitions, not just Products
One glaring difference between the emerging cloud era of the mid-2000s and today’s AI era is the democratization of innovation. At the time, only a handful of large companies like Amazon and Google had the scale and breadth to leverage existing IT infrastructure to offer cloud computing services to external developers and companies. Today, AI innovation is largely coming from startups both large and small. Some of the most prominent AI names at the model, infrastructure, and app layers were founded in recent years: OpenAI (2015), Anthropic (2021), Mosaic (2021), Perplexity (2022), etc.
This is why partnerships and acquisitions have become a more compelling strategy than simply trying to build the best products in-house. We have seen the large hyperscalers race to partner with startups at every layer of the stack to strengthen their existing offerings. Some recent examples include:
And the list goes on.
With record levels of cash on their balance sheets (Amazon with $87B, Microsoft with $81B, and Alphabet/Google with $111B), the hyperscalers are well-positioned to make splashy acquisitions to bolster their AI strategies, or at the very least, continue striking partnerships with the most innovative AI startups.
Open Source Continues To Roll Ahead
While OpenAI (GPT) remains the best-known closed-source model, open-source continues to be more popular. Open-source models are no longer viewed as the ‘inferior’ choice and many practitioners we know are leveraging both open-source and closed-source models based on specific tasks. Since Meta’s Llama-2 OSS model was released, it feels like there have been new performant OSS LLMs released every day. Over the last couple of weeks, we saw four major open-source models launch: DBRX by Databricks, Grok 1.5, Samba-CoE 0.2, and Jamba.
DBRX – Announced by Databricks, DBRX is a transformer-based decoder-only LLM trained by using next-token prediction. It uses a fine-grained mixture-of-experts architecture with 132B total parameters, of which 36B are active input. It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2. This provides 65x more possible combinations of experts and we found that this improves model quality.
Grok 1.5 – Grok 1.5 is a major improvement from Grok 1, boasting increased performance in coding and math-related tasks. Grok 1.5 can also process contexts up to 128K tokens (tokens refer to bits of raw text and context refers to input data). A longer context window allows Grok to have increased memory capacity (up to 16x the previous context length) and enables it to utilize information from substantially longer documents.
Samba-CoE v0.2 – This new model from SambaNova is a subset of Samba-1 that will be available for use next month. Samba-CoE is optimized for general-purpose chat, and is built off the CoE architecture and runs at a rate of 330 tokens per second for a batch size.
Jamba – Jamba, from AI21 Labs, combines transformers with the increasingly popular structured state space model (SSM) architecture that powers models like Mamba. The SSM architecture gives Jamba a larger context window of 256K, demonstrating much higher throughput and efficiency.
Notably in February, Microsoft announced a partnership and investment in Mistral. This is noteworthy considering Microsoft already has an investment and strong interest in closed-model provider, OpenAI (cue the “rivalry” discussions…).
The rush of the Big 5 platforms to embrace open-source will certainly have an interesting impact on the broader ecosystem, and we can expect these organizations to only further innovate in OSS. Creating buzz around OSS models can be beneficial for BigTech (particularly those that cater towards developers), so what might we see from Amazon, Snowflake, and others in this area?

Plenty of Whitespace for Startups, But Big 5 Won’t Be Idle
AWS, Azure, and GCP powered the cloud era to the tune of ~$200B in run-rate revenue, but that didn’t stop startups from scaling in competing areas (just look at Snowflake, MongoDB, Confluent, Elastic, etc.)
During the cloud era, we witnessed many cloud-native applications (Stripe, Netflix, Uber, Airbnb, etc.) being built that took advantage of the billions of dollars of infrastructure spend that AWS, Azure and GCP were investing behind. We foresee a parallel trend emerging within the current AI startup landscape. Large companies can and will be built at every layer of the stack, and we anticipate many of these newer AI startups will try to find asymmetric ways to attack incumbents.
We believe 2024 will be the year of the application. Startups are now enabled to capitalize and build on top of the model, compute, and infrastructure work laid by BigTech and the hyperscalers. Many may also find ways to partner with other players in the AI ecosystem like Nvidia to get access to GPUs and compute in unique ways. At the infrastructure layer, as more startups are leveraging multi-cloud and multi-model architectures, they may look to a non-big tech company that may be less opinionated to help with data movement, model deployment, and training.
All this being said, we shouldn’t expect the Big 5 to rest on its laurels. In fact it’s the exact opposite: they are moving faster than ever, competing aggressively, and not afraid to use their massive balance sheets to protect incumbency. We believe they will continue to do what they can, but they certainly cannot dominate the entire stack. We are excited to see how startups continue attacking asymmetrically to find new ways to compete.
Conclusion
Unlike prior platform shifts in tech where large incumbents remained idle in the face of rising upstarts, the Big 5 cloud providers are doing everything they can to maintain their relevance in the emerging AI ecosystem. They are building at every layer of the stack, from models, to infrastructure, to applications. And if they aren’t building, they are finding ways to partner (or acquihire) with the smartest teams innovating in the space. We fully expect Microsoft, Amazon, Google, Databricks, and even Meta and others to continue surprising us with how quickly they move in the domain.
However, plenty of whitespace for startups remain. The Big 5 will inevitably face mounting regulatory scrutiny, particularly concerning their AI endeavors, as well as bureaucratic hurdles that every large company must contend with. Personally we believe that the application layer is particularly ripe for new, innovative companies to disrupt incumbents. Or as Sarah Tavel from Benchmark eloquently wrote, by “providing a 10x better experience at a fraction of the cost.”
If you’re building an AI company in these areas, we’d love to hear from you!
Please subscribe, and share the love with your friends and colleagues who want to stay up to date on the latest in artificial intelligence and generative apps!🙏🤖