
Podcast Drop: A Conversation with Jeff Huber
What the Chroma CEO has to say about Vector DBs, the GenAI hype cycle, community-led growth, and much more


Happy September! Thank you to our now 1.5K+ subscribers, we appreciate all your support! Please continue to share with colleagues, friends, or anyone you think would enjoy staying current on the latest trends in AI :)
Last week, we had the chance to sit down for an interview with Jeff Huber, cofounder and CEO of Chroma. Chroma bills itself as an “AI-native open source embedding database”, more commonly known as a “vector database”. Vector DBs have taken the AI world by storm over the past year, as they have been a key part of the infrastructure stack powering next-gen AI applications. A number of independent vector database startups have been founded and raised millions of dollars, including Pinecone, Qdrant, Weaviate, and Milvus; not to mention that large public database companies are now offering vector DBs alongside their core platforms (such as MongoDB with Atlas Vector Search).
Jeff is a second-time founder, and in this discussion offered his thoughts on a variety of subjects including why memory in AI even matters, the need for a new type of database, growing and engaging a dedicated developer community, hiring in a competitive market, and much more.
You can listen to the podcast below and read the full transcript here, but in this post we’ve summarized our key learnings and takeaways.

So What Even Are Vector Databases, and Why Do We Need Them?
When querying conventional databases (e.g., relational database), traditional search engines look for rows that match the exact query. These traditional search engines perform keyword-based search, but as a result, they do not take into account the actual meaning of the query. Vector databases on the other hand deal with “vectors” rather than strings and are purpose-built to manage unstructured data. Vector-based searches retrieve documents by meaning and not by keyword matching.
Vector databases are purpose-built to handle the unique structure of vector embeddings making it easy to search, retrieve, and compare values that may be similar to one another. Vector embeddings are the building blocks for many of the Intelligent and Generative Apps that we use today. While Foundation Models provide very high levels of abstraction, they are trained on generalized data and they lack company-specific data and awareness.
By leveraging vector databases, applications can improve their accuracy around similarity search and recommendation systems, ultimately leading to a better understanding of what the user is trying to query. Not surprisingly, the explosion of large language models has propelled the rise and popularity of vector databases.
How Vector Databases Work (A simplified version)1
You enter a query into the application as the user.
The query is sent into the embedding model, which generates vector embeddings. The vector embedding is stored in the vector database, along with the content being indexed.
The vector DB generates the output and returns it to the user as a query result.
When the user makes further queries, it will use the same embedding model to generate embeddings to query the database for comparable vector embeddings. The similarities between vector embeddings are based on the original material from which the embedding was constructed.
Because the answers are dependent on how close or approximate they are to the query, the major factors here are accuracy and speed.

Why Does Memory in AI Even Matter?
Vector embeddings are a type of data representation that carries semantic information to help AI systems Generate and maintain long-term memory. This concept of memory is a critical component of vector databases. With memory, applications can be significantly more personalized and unique, by remembering user inputs. One unique feature of Vector databases is that they provide long-term memory for the FMs, by storing information as vectors.
With the democratization of FMs and the increase of new generative and intelligent apps, there has become a greater need for memory. Today, many generic FMs hallucinate or struggle to make more personalized suggestions, but by leveraging the embeddings for intelligent search and retrieval, these applications can improve their performance and provide more contextually aware, personalized, and relevant responses.
A lot more has to exist and has to exist at the database level. I think that’s the other point here is that just we’re so early to what memory for AI means and looks like, and it’s pretty likely that a learned representation ends up being the best anyways. You actually want to have neural nets running against your data and at this very low level to power retrieval. And that’s how you get the best memory. And if that’s how you get the best memory, that’s what you’ll want to use. Going deeper and going longer, again, our goal is to create program memory for AI. I alluded to earlier in the conversation that viewing cosine similarity search as the end of the road for advancements in programmable memory for AI would be extremely foolish. We’re not going to do that. We’re going continue to aggressively research and build more and more powerful approaches to do that well because it matters. We have to cross the chasm here. - Jeff Huber, Chroma CEO

Why Chroma?
Jeff and his co-founder Anton were intentional from the very beginning about building Chroma as an open-source tool. The benefits of an open-source framework are numerous:
Flexibility: Developers have the option to deploy on the cloud or as an on-premise solution. Chroma supports multiple data types and formats, allowing it to be used in a wide range of applications.
Easy to install: Developers (or anyone with some technical chops) can start using Chroma for free, through a simple pip install and importing the Chroma client. Users can bring their own embedding models, query Chroma with their own embeddings, and filter on metadata.
Engaged community and support: As Jeff recounts, he and Anton released the first version of Chroma on Valentine’s Day (the original Feb 13th launch date got pushed by a day due to a bug fix), and since then have enjoyed phenomenal support from the developer community. This support allowed Chroma’s own team to remain small and nimble while leveraging the community to help improve the product.
I’ll say upfront, in many ways, I think we’ve gotten really lucky, and I think the community ultimately is why the project has grown…The community helped to make it better in terms of giving us feedback, opening up pull requests, and opening up issues. I think we’ve been lucky thus far or our path to this point.
Chroma also keyed on the importance of building integrations with other popular open-source frameworks such as LangChain and LlamaIndex to continue making it easy for developers to build AI applications on top of reliable infrastructure. Per LangChain’s blog post announcing their partnership: “Chroma aims to be the first, easiest, and best choice for most developers building LLM apps with LangChain.”…not a bad vote of confidence!
The confluence of significant interest in AI and vector databases along with Chroma’s ease of use and integrations with frameworks like LangChain led to an explosion in open-source downloads and popularity:

Tips on Hiring, Community-Led Growth, And Other Founder Lessons
As a second-time founder (Jeff’s previous company Standard Cyborg enabled developers to build 3D scanning, analysis, and design into their applications), Jeff had a wealth of helpful tips and feedback on company building:
Do the hard work of getting user feedback at the outset
Months before the first version of Chroma was even released, Jeff “reached out to a bunch of people on Twitter who had tweeted about LangChain and embeddings and all this stuff just to get their feedback on what we were building and see if they shared our opinion.” By directly messaging users and hopping on Zoom calls with them, he was able to generate rich user feedback on what was and wasn’t working in building AI apps, which ultimately led Chroma to gain early adopters and outsized recognition out of the gates.
And yeah, just started training a bunch of users and found that they shared the sentiment that something that was easy to use and powerful didn’t exist. And so we’re like, that’s interesting. Let’s go see where that goes. Let’s follow that trail and see where that goes. And that led us to, again, launching the project in open-source, and now cumulatively, the Python project has crossed 1.5 million downloads since launch and 600,000 plus of those in the last 30 days.
Take the long view
Chroma realizes that at the core of its early success is its community, and they are keen to do everything they can to cultivate and nurture that community properly, versus rushing to aggressively market to those users or monetize them.
Also, if you become obsessed over things like churn and retention, you start doing a lot of bad behavior, which is anti-community. And so you start gathering people’s emails and sending out terrible drip content marketing just to try to keep them engaged. You do weird, bad stuff. And I never wanted to join a community that did that to me.
Obsess about your customers, not your competitors
When asked about the noisy landscape for vector databases, Jeff correctly pointed out that in the open-source community, “competitors” are referred to as “alternatives”. More importantly, he noted that he actually doesn’t pay much attention to others in the space because “it can be a distraction”. The entire market is so early in its development that every alternative (including Chroma) will go through a number of twists and turns as products and user needs evolve. Instead, early-stage founders and builders should obsess about their customers, developers, talent, and product experience which will lead to better outcomes.
I think, in some ways, the first rule of competition is don’t be distracted by the competition. If they were perfect, they would’ve already won. And you’d have no room to be good, and you’d have no room to win.
Conclusion
With many alternatives from both well-funded private companies and established public vendors, vector databases remain a hotly contested market and we fully expect to see many twists and turns as the space evolves. But as Jeff points out, a few things remain unalterable truths in building a big company: a deep understanding of the problem space, an intense obsession with user experience, and of course a little bit of luck!
Funding News
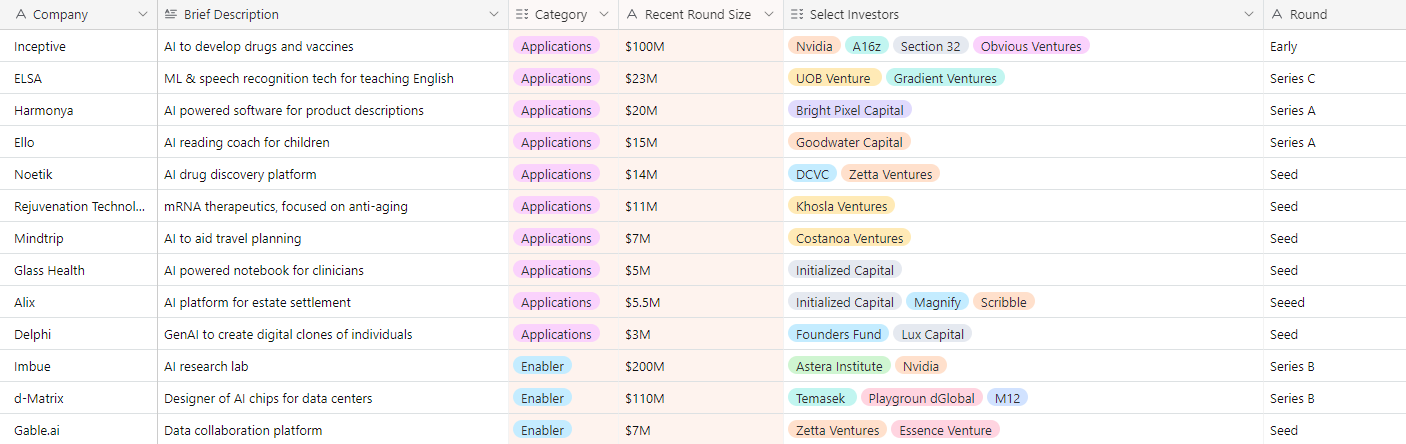
Below we highlight select private funding announcements across the Intelligent Applications sector. These deals include private Intelligent Application companies who have raised in the last two weeks, are HQ’d in the U.S. or Canada, and have raised a Seed - Series E round.
New Deal Announcements - 09/01/2023 - 09/14/2023:
We hope you enjoyed this edition of Aspiring for Intelligence, and we will see you again in two weeks! This is a quickly evolving category, and we welcome any and all feedback around the viewpoints and theses expressed in this newsletter (as well as what you would like us to cover in future writeups). And it goes without saying but if you are building the next great intelligent application and want to chat, drop us a line!
https://lakefs.io/blog/what-is-vector-databases/