
The Compounding Stack ↗️
How micro improvements across data, model logic, and UX create moats in the age of AI


A common question founders ask right now is: where’s the moat for AI apps? In a world where everyone’s using the same base foundation models, how do you actually build something defensible?
The answer, increasingly, is through a series of micro improvements — small, compounding optimizations at every layer above the foundation model. Each improvement may seem trivial on its own, but together, they form a differentiated stack that’s hard to copy and that compounds value over time. It’s not about building another GPT wrapper - it’s about constructing a microstack: a focused system where data, model logic, and UX are tightly coupled and continuously improving.
The best AI companies today are building microstacks: Cursor, Glean, Lovable, Replit, and many of the AI-native companies in the “$100M ARR Club” (however you count ARR) have built tightly coupled data, model, and UX systems that improve with each user interaction.
So how do these systems work and interact with each other?
Let’s dive in.
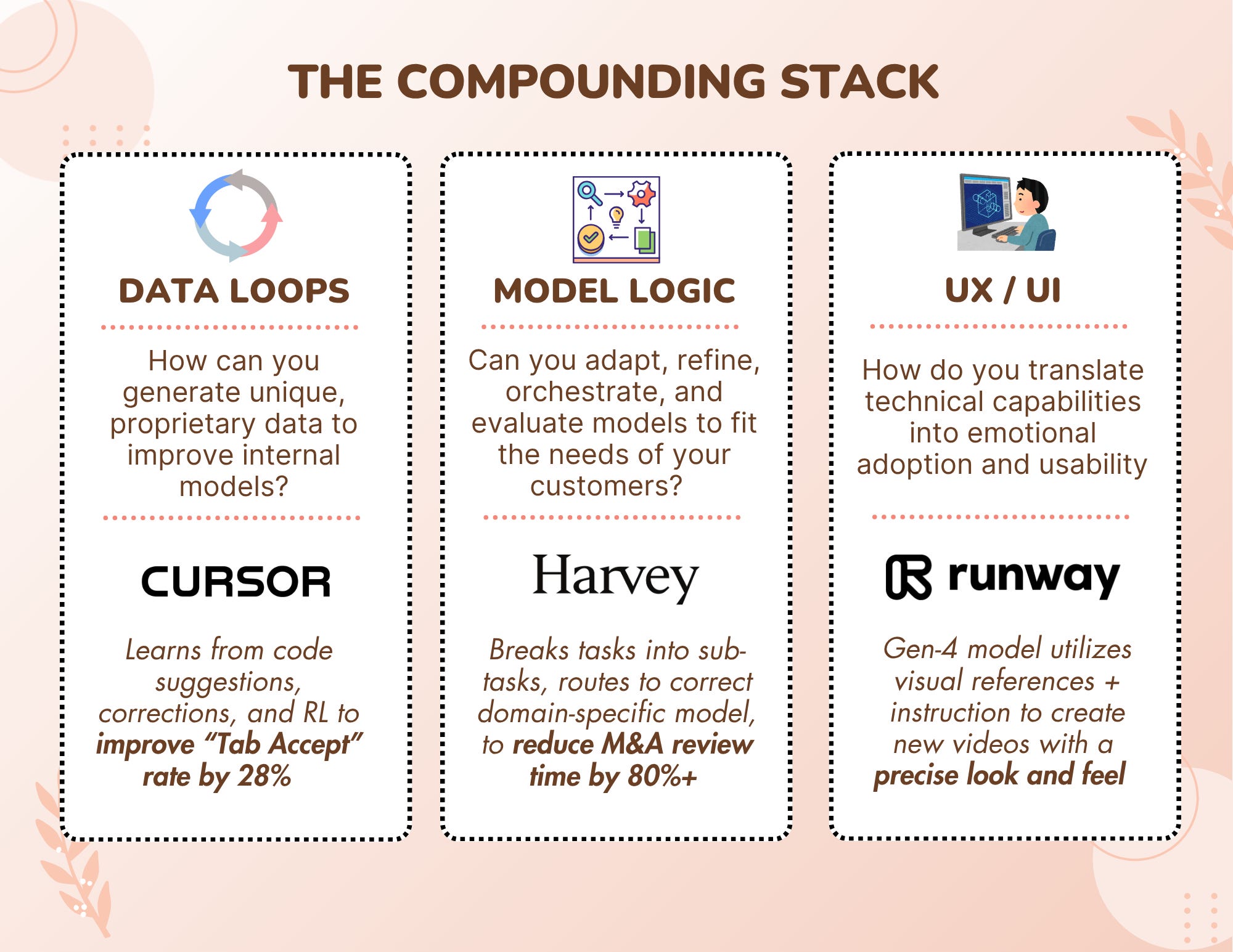
We believe three key pillars that can help startups build a real, durable moat above the model layer where they are likely utilizing a third-party FM from OpenAI, Anthropic, Google, Meta, etc.
Unlike the foundation models themselves, these pillars are more in the control of the startup and allow them to distinguish themselves based on their product and end users.
Data Loops
It’s a common refrain that data is the lifeblood of AI. AI models and systems feed on highly relevant, labeled, curated data, particularly for specialized models.
Less talked about is the data loop - creating and owning a flywheel where your product collects proprietary usage data that makes your product or application better. The proprietary part here is key: while you can use a generalized horizontal foundation model to power your app, if the app itself can i) collect and ii) learn from that data generated in that app, it can lead to a virtuous, referential improvement loop.
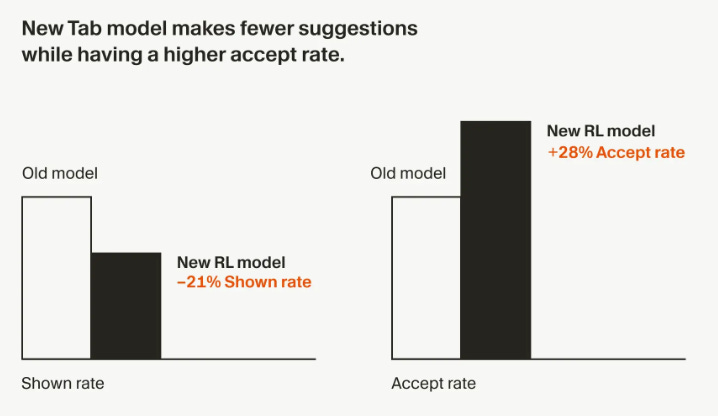
Cursor provides a great case study here. Cursor learns from every code suggestion and correction, understanding when users ‘Tab”, and improving the model based on these behaviors. Through multiple cycles, Cursor can gain a much fuller understanding of user behaviors and intent, and eventually use that to feed/build its own model (and perhaps even wean itself off its massive Anthropic usage to improve gross margins…).
Other top-performing AI apps have built great self-improving data loops. Glean improves search relevance as employees click, query, and refine. Lovable tunes its design model on how users accept or reject visual suggestions. The list goes on.
A subset of the data loop is reinforcement learning (RL). This is about teaching an agent to adapt continuously, often in real-time as goals evolve. The challenge lies in constructing the right datasets and, more importantly, designing reward functions that actually drive the desired behavior. Done well, RL allows you to reinforce the agent when it executes the correct sequence of tasks, gradually aligning its performance with your objectives. And because user interaction is central to this loop, encouraging engagement becomes critical: the more your users interact with the product, the richer your dataset becomes, and the more effectively your agents can be optimized over time.
Model Tuning, Orchestration, and Evaluation
Another layer of differentiation can come from model logic: how you adapt, refine, orchestrate, and evaluate models to create unique behavior. This doesn’t require billions in compute or training new models from scratch. It’s about the clever middle layer: fine-tuning on your data, using retrieval to ground answers, or distilling large models into smaller, faster ones.
Replit’s Ghostwriter, another AI coding tool for developers, is a perfect example of building great logic. Ghostwriter doesn’t simply just call OpenAI’s API; it’s tuned for coding workflows, error correction, and latency. That combination of model logic and domain specificity makes it feel magical. Every improvement in reasoning, context-handling, or memory here makes the product feel smarter without needing a bigger model.
The AI orchestration layer can act as a product’s “central nervous system.” For organizations deploying AI, no single model is optimal for all tasks. An orchestration layer acts as the coordinating brain - deciding which models to use, when, and how. These orchestration layers hide the decision-making from the end user, letting them stay focused on their workflow rather than on model selection.
Decagon and Sierra are good illustrations — their orchestration layers don’t just pass prompts to an LLM, they decide when to use a domain-specific model, when a simple database lookup is enough, and when full generative reasoning is required. Harvey also leverages similar techniques by breaking tasks into subtasks, routing each to the right model, and then stitching the results back together, making the system feel both smarter and more efficient. This level of dynamic routing drives performance.
Model evaluation is a moving target. Because models are constantly evolving and being updated, no single model is ever going to be optimal for every task, thus continuous evaluation is critical. It’s not just about choosing once, but about regularly testing and benchmarking to maximize performance across different workflows as models change.
Hebbia, for example, created their own Financial Services Benchmark to identify which models perform best on finance-specific workflows. The more consistently you run these evaluations, the more likely your models deliver accurate outputs — driving greater customer value and accuracy along with increasing customer retention.
UX
Finally, UX and workflow integration turn intelligence into retention. The best AI startups don’t just add chat boxes; they embed AI naturally into user workflows. That means context persistence, seamless integrations, and UI polish that make users want to stay inside the loop.
Great UX is what translates technical capability into emotional adoption. It’s the difference between a user trying your app once and building it into their workflow. Cursor and Replit make AI feel native to the act of coding. Perplexity turns information retrieval into a conversational experience rather than a search chore. Runway’s UI makes generative video feel like creative collaboration, not prompt engineering. Each of these products succeeds not just because they’re technically advanced, but because their design makes that intelligence approachable, consistent, and delightful.
And of course there is the often hard-to-describe feeling of taste. Taste is often defined the ability to decide what not to build. It’s the discipline to remove friction instead of adding features, and to make every interaction feel intentional. Linear embodies this perfectly — not just in its visual minimalism, but in how every motion, delay, and interaction communicates focus. You can feel when something has taste: it’s fast, quiet, and confident.
The lesson from products like Notion AI, Harvey, or Runway is clear: AI is the engine, but UX is the transmission. The easier it is for users to express intent, see results, and refine outputs, the faster your data and model loops spin — and the deeper your moat becomes.
Putting it all together
A defensible AI product isn’t just a thin wrapper around a foundation model — it’s the opposite. Instead of being fully dependent on someone else’s FMs, you leverage it while continuously growing smarter through the micro improvements layered above it.
Data moats come from proprietary feedback loops and user signals that fuel adaptation.
Model moats are built through orchestration, evaluation, and reinforcement techniques that maximize performance as models evolve.
UX moats turn intelligence into retention, embedding AI seamlessly into workflows so users stay engaged and keep generating data.
It’s the combination of these layers that creates compounding advantage. Each improvement may look small in isolation, but together they form a microstack that reinforces itself — better UX drives more data, better data improves models, and better models create even stickier UX. Over time, this flywheel compounds into a differentiated system that’s hard to copy and only gets stronger with scale.
As OpenAI execs repeatedly say: the best way for startups to thrive is to bet on the underlying models getting better, not stagnating. In this world, strong data loops, smart model logic, and brilliant UX/UI are the keys to entering the $100M ARR Club!
The insight about microstacks being the real moat for AI apps is profoundly accurrate. This tight coupling of data, model, and UX is indeed where the true diffrentiation lies.