
The AI Watchdogs are Coming
Regulators now have AI in its crosshairs; how should companies prepare?


Please share the love with your friends and colleagues who want to stay up to date on the latest in artificial intelligence and generative apps!🙏🤖
There’s a point in every new platform shift when the tech hype begins to capture the zeitgeist, and the regulators come knocking. The Telecommunications Act of 1996, the first significant overhaul of United States telecommunications law in 60 years, coincided with the birth of modern browsers and the resulting explosion in Internet usage. As social media grew in scale and reach (not to mention the Facebook / Cambridge Analytica scandal), the EU implemented major data privacy laws in 2018, followed shortly by California in 2020.
Now today, with ChatGPT and similar AI applications being used daily by millions, artificial intelligence is again in the crosshairs of policymakers and regulators.
In the past two weeks alone:
The Biden Administration announced they are seeking additional input on AI safety measures from the public, a first step in what’s likely to result in stronger measures for AI safety
Senate Majority Leader Chuck Schumer formally launched a proposal to establish rules around AI
Italy’s data regulator issued a temporary emergency decision demanding OpenAI stop using the personal information of Italians that’s included in its training data which halted the use of ChatGPT in Italy
Clearly, there is plenty of excitement around the benefits of AI (of which this Substack has been a proponent!). But we would be wilfully negligent if we didn’t balance that excitement by detailing some of the risks and harms associated with AI proliferation, and what the resulting policy could look like. While there are plenty of good arguments against AI regulation, particularly that foreign adversaries are unlikely to halt or even slow down their advancements in the space, our view is that it is better for founders and operators to be aware of what may come and prepare accordingly. We agree with David below that the government should help shepherd a path, not “create roadblocks”.
In this post, we will discuss the significance of data privacy in the context of LLMs, the potential associated risks, and how companies can maintain a competitive edge by utilizing their own proprietary data without it getting incorporated into other LLMs.
Let’s dig in.

Two of the primary arguments in favor of AI regulation revolve around:
Data privacy → The use of private data and PII used in LLMs and black box models.
Ethical and safety considerations → Discrimination, biases, and the spread of harmful information.
Of course, there are other larger concerns raised about the specter of AI, particularly the existential risks potentially posed by AGI, but we’ll focus on the above two real and immediate concerns in this post.
Data Privacy
Data privacy refers to the protection of personally identifiable information (PII), which could include financial information, health information, social security numbers, home addresses, and more. In the digital age, data privacy has become increasingly important as more companies and organizations collect information and share it across online platforms (think about all those targeted ads you receive!).
In the specific context of LLMs, these models are trained on large public datasets (e.g., C4, The Pile, The Bigscience Roots Corpus, OpenWebText, LAION, and more). However, in order to improve the models, the LLMs also collect data from user interactions. For example, when a user asks a question to ChatGPT, they often input additional context or information to the model. In doing so, ChatGPT is collecting potentially proprietary data or information, which the LLM then feeds back into its system to create better outputs.
Misuse of data can result in:
Lack of transparency: LLMs can be complex and difficult to understand, which can make it hard to determine how personal data is being used or why certain decisions are made.
Lack of control: As AI is used to collect and analyze vast amounts of personal data, there are rising concerns about privacy and the potential for misuse of personal/proprietary information or copyright infringement (as we saw with the Github CoPilot Lawsuit).
Infringement of data privacy is ultimately what led Italy to take the drastic measure of banning ChatGPT, citing that OpenAI was processing users’ local data in breach of GDPR. OpenAI responded by geoblocking ChatGPT in Italy, and there’s no clear indication as to when it will be unblocked. While we believe Italy is on the extreme side of the spectrum for fully banning ChatGPT, it’s clear that perception of data privacy infringement can lead countries (mostly in Europe) to take drastic action (e.g. see Germany).
Ethical and Safety Concerns
A second major concern raised by AI skeptics is the potential for heightened discrimination and bias. AI algorithms are only as unbiased as the data sets on which they are trained. If the training data reflects historical discrimination or biases, the AI system may perpetuate and amplify these biases. For example, AI systems used in hiring processes may inadvertently discriminate against certain groups of people, such as women or minorities, if the training data is biased toward past hiring patterns. In 2022, the US Equal Employment Opportunity Commission (EEOC) issued guidance for employers on the shortcomings of AI-based hiring tools (such as evaluating a candidate's facial expressions which can perpetuate bias). Similarly, AI systems used in criminal justice may reflect historical biases in sentencing, leading to unjust outcomes.
AI can also enlarge and hasten the spread of misinformation in a variety of ways:
Fake news generation: AI algorithms can be trained to generate fake news articles or posts that are designed to look like legitimate news stories. These articles can then be spread through social media or other online platforms, potentially reaching a large audience before they are identified as fake.
Content recommendation algorithms: Many online platforms use AI-powered algorithms to recommend content to users. If these algorithms are not designed to prioritize accuracy or legitimacy, they can inadvertently recommend false or misleading information to users, potentially leading to the spread of misinformation.
Deepfakes: AI-powered deepfakes are synthetic videos or images that use machine learning algorithms to superimpose one person's face onto another person's body. These deepfakes can be used to create false information that appears to be real, such as a video of a politician saying something they never actually said.
A recent real-life example of AI run amok happened in Venezuela, where AI video tools like Synthesia were used to create fake American newscasters which were spreading disinformation. It’s not out of the realm of possibility that we will see more of these kinds of “fake campaigns” run globally.

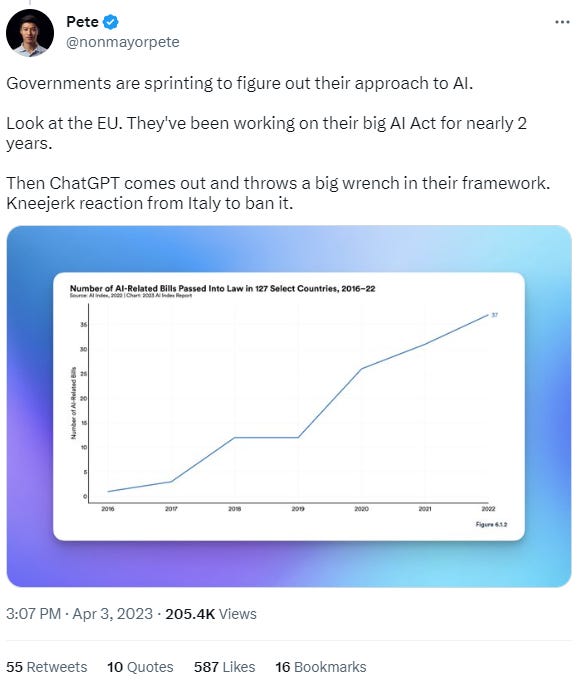
Current Regulatory Frameworks
There are several regulatory frameworks related to data privacy around the world, including the European Union's General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) in the United States. These laws have been created to protect individuals' personal data from being misused or mishandled by companies; however, LLMs are now increasing the scope and impact of data privacy regulations are likely to expand. A few laws and frameworks include:
Europe’s GDPR rules cover the way organizations collect, store, and use people’s personal data and protect the data of over 400M people.
California’s Consumer Privacy Act (CCPA) is a data privacy law that gives California residents the right to know what personal information is being collected about them by businesses, and the right to request that this information be deleted or not sold to third parties.
EU AI Act is an Act that was initially drafted in the EU in 2021, but has been picking up steam. The act focuses primarily on strengthening rules around data quality, transparency, human oversight and accountability. The AI Act follows a classification system that determines the level of risk AI could pose to the health, safety, and fundamentals of a person.
NYC Local Law No. 144 regulates the use of automated employment decision tools wherein hiring decisions are made or substantially assisted by algorithmically-driven mechanisms (e.g., AI systems).
AI Governance Strategy for Companies Leveraging LLMs
As enterprises consider how they can create a competitive advantage against their competitors, much of it comes down to establishing a data moat, or a data flywheel. However, with LLMs, it has become increasingly easy to inadvertently share information. This can happen when proprietary source code is accidentally shared for a scan in GitHub CoPilot, or when an employee asks ChatGPT to create an internal memo for a new product launch.
As companies start leveraging these LLMs across a variety of different use cases including 1) Leveraging LLMs off the shelf (e.g., OpenAI API); 2) Leveraging LLMs but fine-tuning the models by bringing in their own proprietary datasets (e.g., HuggingFace models + proprietary datasets); or 3) using GenerativeAI like tools such as ChatGPT, GitHub CoPilot, and JasperAI in-house, companies should consider how to create an AI governance strategy.
Here are a few key questions to consider:
Are there any data privacy risks associated with leveraging an LLM?
If I bring in my own data and train an LLM, will the model provider ultimately get access to that data as well?
What are the specific policies and controls I should have to ensure that my employees are not inputting proprietary information into these models?
How do we evaluate and moderate tools to ensure the company has control of the systems so there are no model biases that the company is accountable for?
We are starting to see companies emerge in this category that are helping create frameworks around AI Governance strategies and to ensure AI systems are safe:
CredoAI is an AI governance software/SaaS platform that organizations use to bring oversight and accountability to the procurement and development, and deployment of their AI systems. Learn more about the Credo story here.
Stratyfy is a provider of predictive model development. Stratyfy’s tools helps build, test, deploy and optimize underwriting and fraud models; provide detailed, interpretable diagnostics of all predictions; self-check models to ensure they meet even the strictest regulatory standards; & detect any inherent bias.
OpenAI announced a program called “Bug Bounty Program” which is designed to report vulnerabilities, bugs, or security flaws you discover in OpenAI systems. Full details here.

How Should Startups Prepare?
As of today, only Italy has taken the step of actually banning an AI application (ChatGPT), and most countries do not have an AI-specific regulatory structure in place. Some nations like India have explicitly opted against regulating AI from a government level today, identifying AI as too “significant and strategic”.
While there are no concrete indications of exactly what regulations will look like, we believe there are still several steps AI companies can take to prepare ahead of time and stay in the “good books” of policymakers:
Self-regulation → One of the easiest ways to at least stave off external regulation is for industry members to monitor and enforce their own standards, and ensure consumer protection. In the case of AI, companies can start building internal guardrails to block sensitive PII from entering black-box models, and create moderation tools to reduce biases. For example as mentioned above, OpenAI just launched a bug bounty program, inviting community members to find vulnerabilities in their systems for a monetary prize.
Work with regulators in helping draft initial policy → Given we are still at the very early stages of AI regulation, this is a great opportunity for industry proponents to work alongside policymakers to draft an initial framework. While BigTech has lobbied the US and EU governments for years, there is a ripe opportunity for industry participants (startup CEOs, academics, venture capitalists, etc.) to help policymakers understand how large language models work, why artificial intelligence can be massively beneficial to the larger economy, and vital to national interests. A recent example involved a US Senate hearing in March, where a Brown CS professor and the CEO of RAND testified on the “risks and opportunities of AI”.
Generate user love → Perhaps the most effective lobbyist for AI is from the consumers themselves. Within Italy, there was backlash from users who were hooked on ChatGPT and suddenly found themselves blocked from using it. The same is likely to happen with any AI application that consumers are utilizing daily, which makes the case against regulation stronger. Startups building a product consumers “can’t do without” will be in a good place here.

Funding News
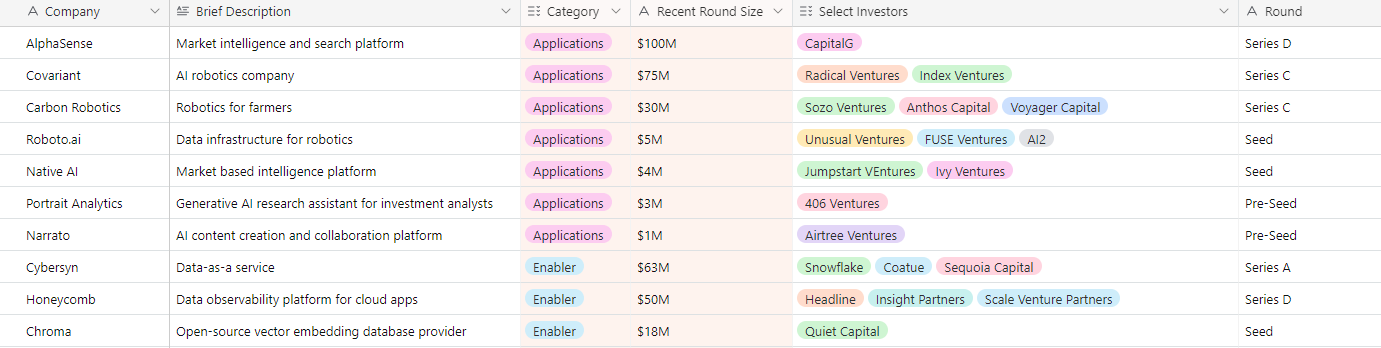
Below we highlight select private funding announcements across the Intelligent Applications sector. These deals include private Intelligent Application companies who have raised in the last three weeks, are HQ’d in the U.S. or Canada, and have raised a Seed - Series E round.
New Deal Announcements - 03/31/2023 - 04/13/2023:
We hope you enjoyed this edition of Aspiring for Intelligence, and we will see you again in two weeks! This is a quickly evolving category, and we welcome any and all feedback around the viewpoints and theses expressed in this newsletter (as well as what you would like us to cover in future writeups). And it goes without saying but if you are building the next great intelligent application and want to chat, drop us a line!
You have made a great point about the scenario. I agree that regulators often lag behind breakthrough technologies because they only act when the technologies have a significant impact on society. The AI development saga shows us that democratic society and regulators need to monitor the "momentum" of emerging technologies, not just their "mass". Momentum is mass times velocity, and AI has certainly grown at an astonishing speed.