
Data Labeling in the Era of AI
How advanced models like Llama 3 underscore the necessity of "high quality annotated data"


The big news in AI recently was undoubtedly Meta releasing Llama 3 on April 18th. Quickly dubbed as the “most capable open source model” to date, Llama3 featured two model weights, with 8B and 70B parameters, and claims to measure more favorably on several benchmarks relative to Gemma 7B, Mistral 7B, and Claude 3.
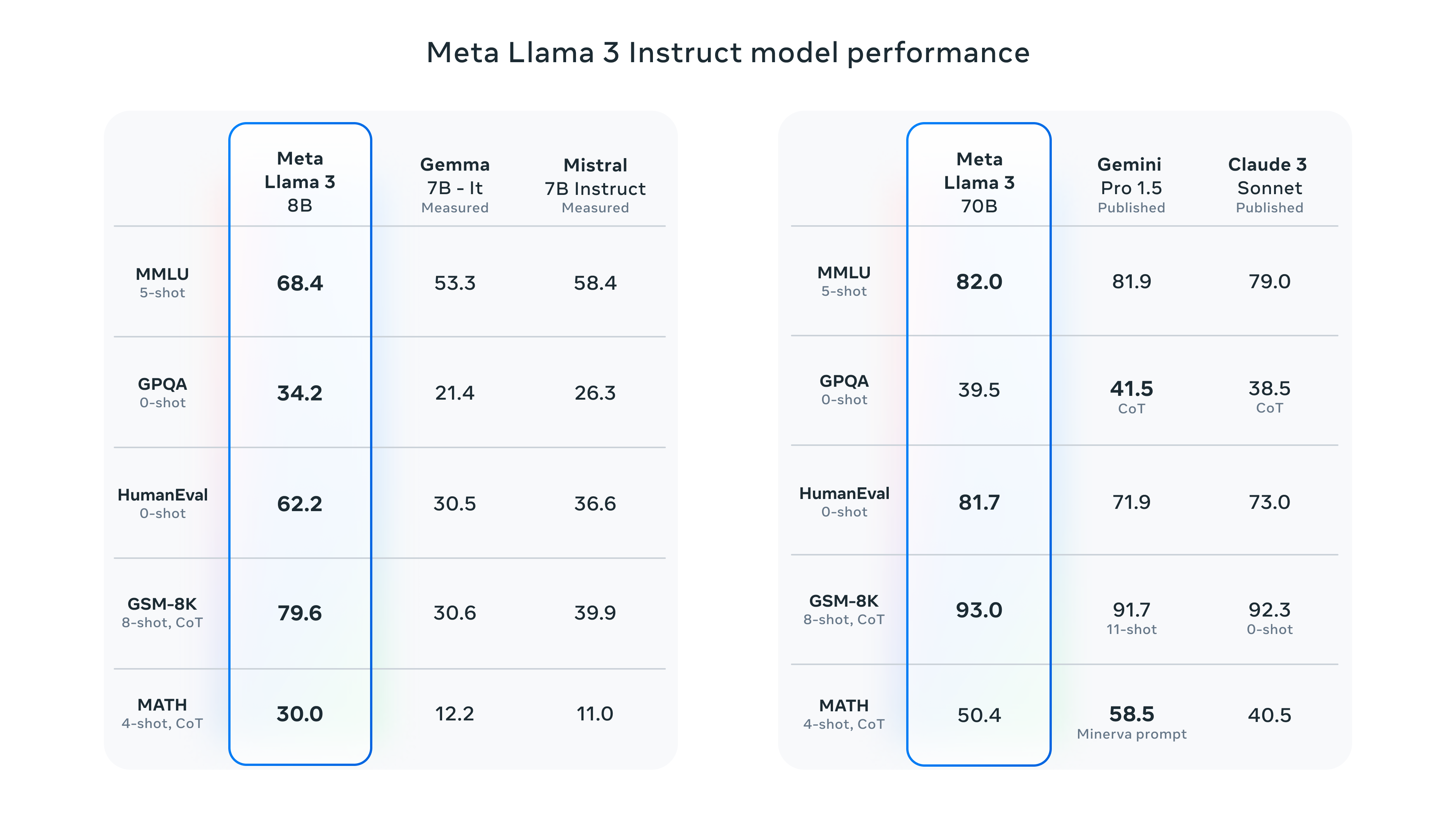
While the initial euphoria was (understandably) around the massive context windows and top marks in public benchmarks, it was one of the less hyped aspects that we thought was the most interesting:
In an interview on the Dwarkesh Podcast, Mark Zuckerberg commented:
“The 8 billion is nearly as powerful as the biggest version of Llama-2 that we released. So the smallest Llama-3 is basically as powerful as the biggest Llama-2.”
So what was instrumental in driving Llama3’s performance relative to Llama2, if not size? The answer is in the data. Meta was able to train Llama3 with high-quality annotated data, revealing that data quality may matter more than the volume of data in training a model.
Martin Casado, GP at Andreessen Horowitz, echoed a similar point, tweeting that LLMs are not as restricted on CPU or size of data, but that the main bottleneck is access to “high quality annotated data.”

So what is data annotation anyway, and why is it important?
Let’s dive in
What is Data Annotation And Why Is It Important?
Data annotation is the process of labeling, identifying, and classifying specific elements in data to train ML models. This annotated data should serve as a ground truth for the model to predict and respond to real-world data and information.
In a pre-LLM world, drawing bound boxes around objects (as depicted below) was a common task in computer vision, especially in object detection and image segmentation applications. Today, in a post-LLM world, data annotation has evolved into a broader array of tasks including cleaning, sorting, and filtering data. Many of these LLMs are often pre-trained on vast datasets and then fine-tuned for specific tasks.

At the core, the success of a model relies on accurately trained data. These models are trained on billions of diverse datasets including text, internet articles, videos, images, and more. Poorly labeled data and inaccurate annotation can lead to incorrect conclusions, biased models, and unreliable AI systems. Many of us have heard of the '“garbage in, garbage out” saying. If you start with poorly trained data (e.g., the model thinks that a “stop” sign is a “go” sign), then the model will draw wrong conclusions about when a car should go vs. stop.
In an article questioning whether or not we are “running out of training data”, The Information describes how “developers could experiment with retraining models on a smaller, high-quality subset of their original training data to improve their performance”, demonstrating the critical importance of why having high-quality training data is valued among developers building in ML.
Where Are We In The Evolution of Data Annotation?
Inba Thiru wrote an excellent blog post last month detailing the evolution of data labeling techniques, arguing that there were three main phases of data labeling and annotation:
Fully Manual → The traditional method employed by most organizations, where all data labeling and annotation is outsourced to typically low or mid-cost human annotators, often offshore.
Semi-Supervised → A middle ground between manual and fully automated approaches, where software is used to help augment and streamline the annotation process but human oversight is still required.
Fully Automated → The “holy grail”, where advanced techniques such as AI and machine learning algorithms are employed to fully automate data labeling with software, and human / manual intervention is no longer required.
While in the “Pre-LLM” world, data annotation and labeling was still a very manual process (Amazon launched Mechanical Turk way back in 2005), we are seeing more and more “Semi-Automated” and “Automated” vendors pop up in recent years. Startups like Scale, SuperAnnotate, Snorkel, and others have gathered traction and landed major logos by offering a spectrum of software + services enabling enterprises to complete their data labeling and annotation at scale.
From the market checks we’ve done, many large customers prefer the “Semi-Automated” approach, where a thin layer of human services enhances the underlying software. Why have humans “in the loop” at all? Though we are moving past the traditional use cases of “draw a bounding box around a stop sign”, there are still plenty of edge cases and domain-specific data sets where manual intervention is helpful. Many of the data analysts and engineers working with annotators emphasize the need for accessing and running quality checks with the humans in the loop.
While humans may not be made redundant in the near-term, we are certainly marching towards being “fully automated” in the long term.

Who is competing in this space?
The “Data Collection and Labelling” market is large, with some estimates pegging the TAM at ~$12B today growing to ~$30B by 2030. This massive global spend has attracted a wide range of competitors, ranging from mature BPOs to scaled startups and emerging entrants.
Scale AI
Perhaps the largest and most well-known startup in the category is Scale AI, founded in 2016 and originally focused on providing data labeling and annotation for machine learning models. Early traction came from use cases centered around autonomous vehicles, but the company has since developed a platform with a suite of products for Generative AI & RLHF, testing and evaluation, LLM optimization and more. The expansion has not gone unnoticed by the market; annual revenue is estimated at ~$700M+ and Accel is said to be leading a new investment into Scale at a whopping $13B.
SuperAnnotate
SuperAnnotate was founded in 2018 by two brothers who dropped out of their PhD programs when they realized they could apply their research accelerating pixel-accurate annotations into the real world. Originally focused on image annotation for mostly computer-vision use cases, SuperAnnotate has expanded to supporting multi-modality and enabling enterprises to fine-tune, explore, and orchestrate their data more efficiently. Their product suite aligns with a thesis behind a “thin layer” of services augmented with software tools. Current customers include AI-centric companies like Databricks and Adept, as well as more “traditional” companies like Qualcomm and Motorola.

Snorkel
Snorkel began life in 2015 as a research project in the Stanford AI Lab where five researchers “set out to explore training data programming, a new interface layer for machine learning”. The team then spun out in 2019 to build a commercial company, quickly receiving funding from Lightspeed, Greylock, and others. Today, Snorkel offers two main products: Snorkel Flow to programmatically label and curate data for AI models; and Snorkel Custom, a more white-glove approach applying Snorkel AI experts to accelerate enterprise adoption of AI.

Others
There are plenty of other companies in the space, ranging from:
Traditional manual vendors (e.g. Appen, Mechanical Turk, Wipro)
Software-enabled vendors (e.g. Labelbox, HumanSignal, Hive, Surge, Invisible)
And many additional emerging startups (e.g. Data Curation companies like Cleanlab, Datology, and Visual Layer that aim to improve data quality and accuracy for LLMs), and other newer entrants like Refuel.ai
Conclusion
There is no doubt that the resurgence of interest in AI & ML and the evolution of advanced models like Llama 3 has accelerated the need for high-quality annotated and labeled data. Semi-supervised vendors like Scale, SuperAnnotate, and others are likely benefiting from these trends, and we don’t expect the appetite for high-quality data to recede anytime soon.
While the market for data annotation is certainly large, there are a few questions we believe should be top of mind:
Customer concentration → Will just a handful of large model providers (e.g. Meta, Google, OpenAI) dominate the need for data labeling, or will all enterprises require this in some form or fashion?
Margins → Traditionally manual data labeling operates at low margins given the commoditization of human labor. For example Appen, an Australian data labeling company using mostly manual services, operates at 36% gross margins and carries a market cap of ~$150M despite nearly $300M in revenue. How do the new vendors avoid this fate and trade more like pure software companies?
Evolving techniques → There is a school of thought that we are in an interesting “middle ground” era of AI where the need for high-quality data is actually peaking and that there will be other techniques to fulfill model requirements (like synthetic data or reusable data). How can vendors in this space build and maintain moats in an evolving ecosystem?
We are tracking this space closely and are excited to see how things play out!

Please subscribe, and share the love with your friends and colleagues who want to stay up to date on the latest in artificial intelligence and generative apps!🙏🤖
Data is intensely valuable. That's for sure. However, this article does not do a sufficient job of distinguishing between high quality data and data annotation? How much of the LLAMA 3 data is annotated? (Not a public statistic.) The trend we observe is that the technology is moving significantly toward self-supervision with minimal intervention, suggestion the annotation market is declining although the overall data market is increasing. This is the real message.
These thoughts are captured in my Annotation is Dead blog from earlier this year. https://medium.com/@jasoncorso/annotation-is-dead-1e37259f1714